Re0:从零开始的机器学习竞赛入门
前情提要:报名参加了第二期Datawhale 2024 年 AI 夏令营的机器学习方向,本篇作一个笔记的汇总。
TASK1:五分钟跑通baseline 一站式体验真方便
首先在task1中明确这次学习的任务:基于讯飞开放平台的电力需求预测挑战赛,一边学习一边优化模型,提高预测分数。
背景说明
1. 讯飞开发者大赛 电力需求挑战赛
-
官方链接:https://challenge.xfyun.cn/topic/info?type=electricity-demand&ch=dw24_uGS8Gs
-
任务:给定多个房屋对应电力消耗历史N天的相关序列数据等信息,预测房屋对应电力的消耗。
-
数据格式:
特征字段 字段描述 id 房屋id dt 日标识,[1,N] type 房屋类型 target 实际电力消耗,预测目标 -
判准:预测数据与真实数据的均方差:

2. 飞桨AI Studio
-
基于百度深度学习开源平台飞桨的人工智能学习与实训社区,为开发者提供了功能强大的线上训练环境、免费GPU算力及存储资源。
3. BML codelab
- 百度的一站式AI开发平台
基本来讲是这个流程:官方在飞桨AI Studio创建了项目,我们把项目fork下来使用BML进行在线开发,此时里面已经包含了训练集和测试集,以及一段baseline代码。我们在BML跑出结果,与测试集合并后提交到讯飞的比赛平台。之后平台会对比提交结果与真实数据,根据判准计算均方差给出最后的分数。
一切都很新奇
好啦~我们经过一系列注册登录认证,来到这样一个页面👇
点击全部运行,你获得了submit.csv(白色品质)。
一通捣鼓,我们把它提交到比赛平台,获得了第一个分数:

Great!但是。。。我们到底做了什么呢?
下面小编带大家看看,我们,或者说baseline代码到底做了什么。
我们要干什么?
首先我们需要明确一下,我们这项任务的输入和输出,也就是:
我们根据什么数据生成什么数据,最后需要提交什么数据?
这里得先简单说明两个词:
- 训练集:相当于带了标答的试卷,我们要根据训练集训练模型,让模型学会做题。
- 测试集:相当于一张空白的模拟卷,我们训练完了模型,要检验它的学习成果,就要让它独立给出这张卷子的答案。我们最终向平台提交的文件,就是写过答案的卷子。
然后就可以回答上面的问题了。
一起复习一下赛题的数据说明:
赛题数据由训练集和测试集组成,为了保证比赛的公平性,将每日日期进行脱敏,用1-N进行标识,即1为数据集最近一天,其中1-10为测试集数据。数据集由字段id(房屋id)、 dt(日标识)、type(房屋类型)、target(实际电力消耗)组成。
这里说得不太详细,我们可以结合我们实际得到的训练集(train.csv)和测试集(test.csv)来看一看。
先看看训练集,大概长这样
| id(房屋id) | dt(过去第几天) | type(房屋类型) | target(实际电力消耗) |
|---|---|---|---|
| 00037f39cf | 11 | 2 | 44.05 |
| 00037f39cf | 12 | 2 | 50.672 |
| 00037f39cf | 13 | 2 | 39.042 |
| 00037f39cf | 14 | 2 | 35.9 |
| 00037f39cf | … | … | … |
| 00037f39cf | 506 | 2 | 33.141 |
| 00039a1517 | 11 | 4 | 51.702 |
| … | … | … | … |
里面列出了一大堆房屋及其类型,以及每个房屋过去某天的电力消耗。
可以看到,训练集给出了从过去第11天开始,到过去几百天的数据,而最近10天的数据是没有的。
最近10天的数据在哪呢?在测试集:
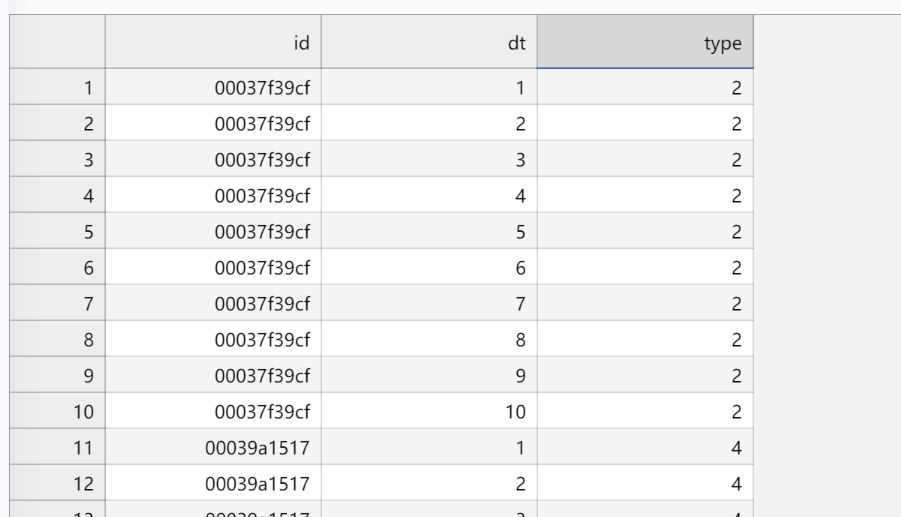
可以看到测试集里列出了所有房屋最近十天的数据,但缺少了最有用的一列,也就是 target(实际电力消耗)。这就是留给我们的空,需要我们填写的答案。
实际上这个测试集没有给出任何未知信息,只是为了输入格式的统一,以及提供一个评判标准,即检验对最近10天的预测结果。
所以实际上,我们的目标,就是要根据这么一个数据集,训练出一个模型,让它预测出给定房屋在某天的电力消耗,使其尽可能准确。
最终我们要用它预测最近10天不同房屋的电力消耗,将其提交到平台上。平台手握实际数据,并计算出和我们预测数据的均方差,这也就是我们得到的评分。
通过测试后,如果我们的分数足够低,就证明了我们的模型能较准确地预测房屋的电力消耗,实际上该模型就不止能推测最近10天,而理论上能预测未来任何一天的电力消耗了。
baseline是怎么做的?
首先看看baseline的代码,它很简单,也有充分的注释:
1 | # 1. 导入需要用到的相关库 |
具体代码中的方法我就不赘述了,这里其实只用到pandas库,可以参考pandas中文文档。
下面是官方的代码精读:
-
导入库:首先,代码导入了需要用到的库,包括
pandas(用于数据处理和分析)。 -
读取数据:代码通过使用
pd.read_csv函数从文件中读取训练集和测试集数据,并将其存储在train.csv和test.csv两个数据框中。 -
计算最近时间的用电均值:计算训练数据最近11-20单位时间内对应id的目标均值,可以用来反映最近的用电情况。
-
将用电均值直接作为预测结果:这里使用
merge函数根据'id'列将test和target_mean两个DataFrame进行左连接,这意味着测试集的所有行都会保留。 -
保存结果文件到本地:使用
to_csv()函数将测试集的'id'、'dt'和'target'列保存为CSV文件,文件名为'submit.csv'。index=None参数表示在保存时不包含行索引。
简而言之,这段代码读取训练集,把相同房屋id(也就是同一个房屋)过去11-20天的平均电力消耗,作为过去1-10天(即我们要预测的部分)中每一天的电力消耗预测结果,并将结果写入测试集,输出最终可以提交到平台的文件。
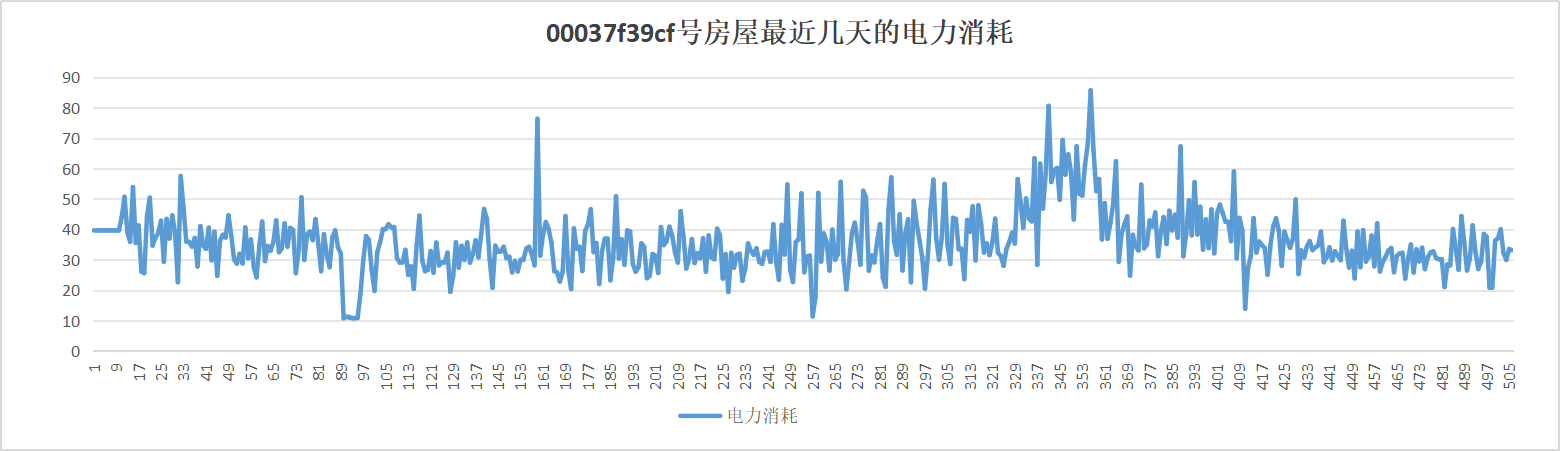
以某个房屋为例,如果把我们的预测结果(过去1-10天)和实际数据(过去11天及以后)放在一起,那么它大概长这样。
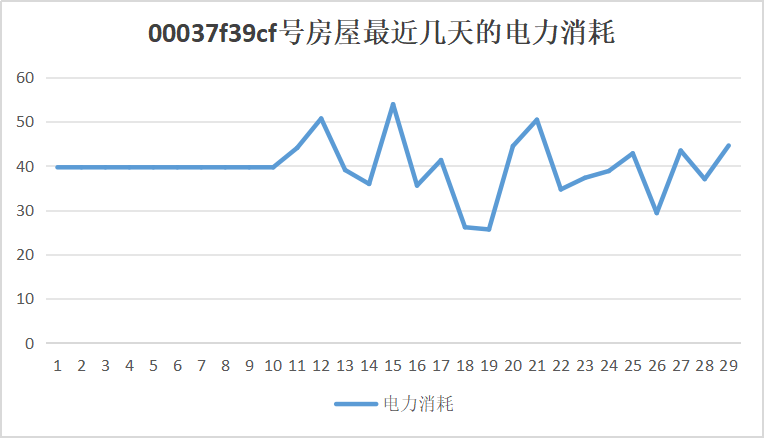
这是一个经验模型(使用均值作为结果数据)。我们暂时完全没有用到机器学习,仅仅用最原始的统计方法给出了一个粗糙的预测结果。
以上代码为何能用来完成赛事要求?
电力消耗本身波动范围不会太大,且具有一定的周期性。此外考虑实际情况,电力消耗在短期是相对平稳的(季节相同、作息惯性等),因此可以基于前几天的平均值预测后几天。
当然,它完全称不上准确,但也差不到太离谱,它将作为我们后续模型的baseline,见证我们的每一次成长。
最佳baseline评分:373.89846
附预测后00037f39cf房完整电力消耗折线图: